How to Display NOAA CLASS data in SIFT
This post will describe how to get data from CLASS to display in SIFT. Latency in CLASS for GOES-16 data is really good — typically less than 3 hours, often closer to 2.
NOTE: To do this, you need a reasonably recent version of SIFT, later than 0.8.4. The latest version is available here: ftp://ftp.ssec.wisc.edu/pub/sift/dist/
The ‘Front Door’ to class (link) looks something like what is below. Notice the ‘Please select a product to search’ drop-down menu bar right above that image that includes San Francisco and the central Valley of California.
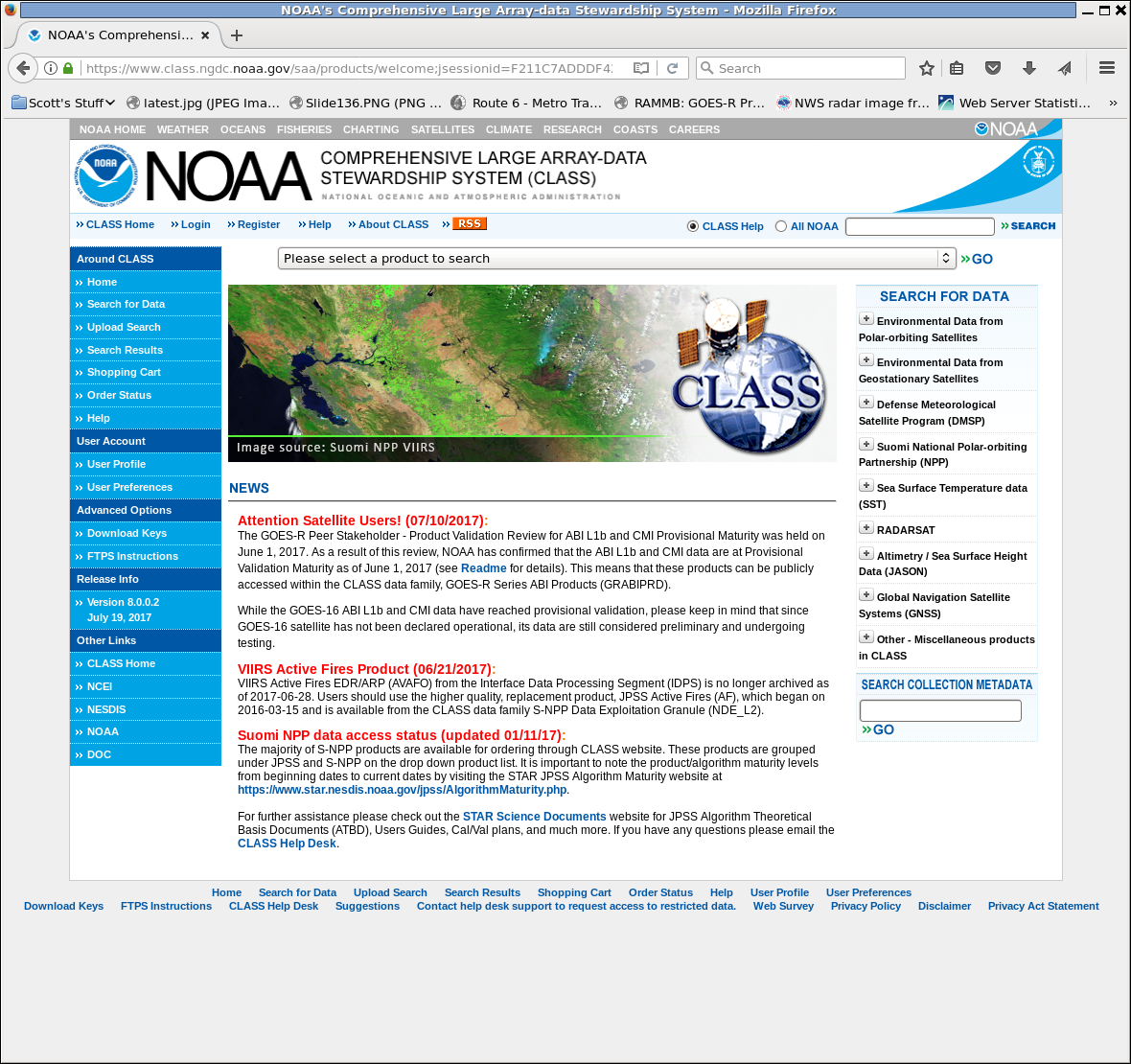
When you click on ‘Please select a product to search’, you will see quite a long list. The product you want to choose is GOES-R Series ABI Product (GRABIPRD). ‘Partially Restricted’ means — at the time of this writing — that data are only available back to Day 1 of Provisional Data — 1 July 2017. Data back to the start of the data flow (in January 2017) may eventually become available.
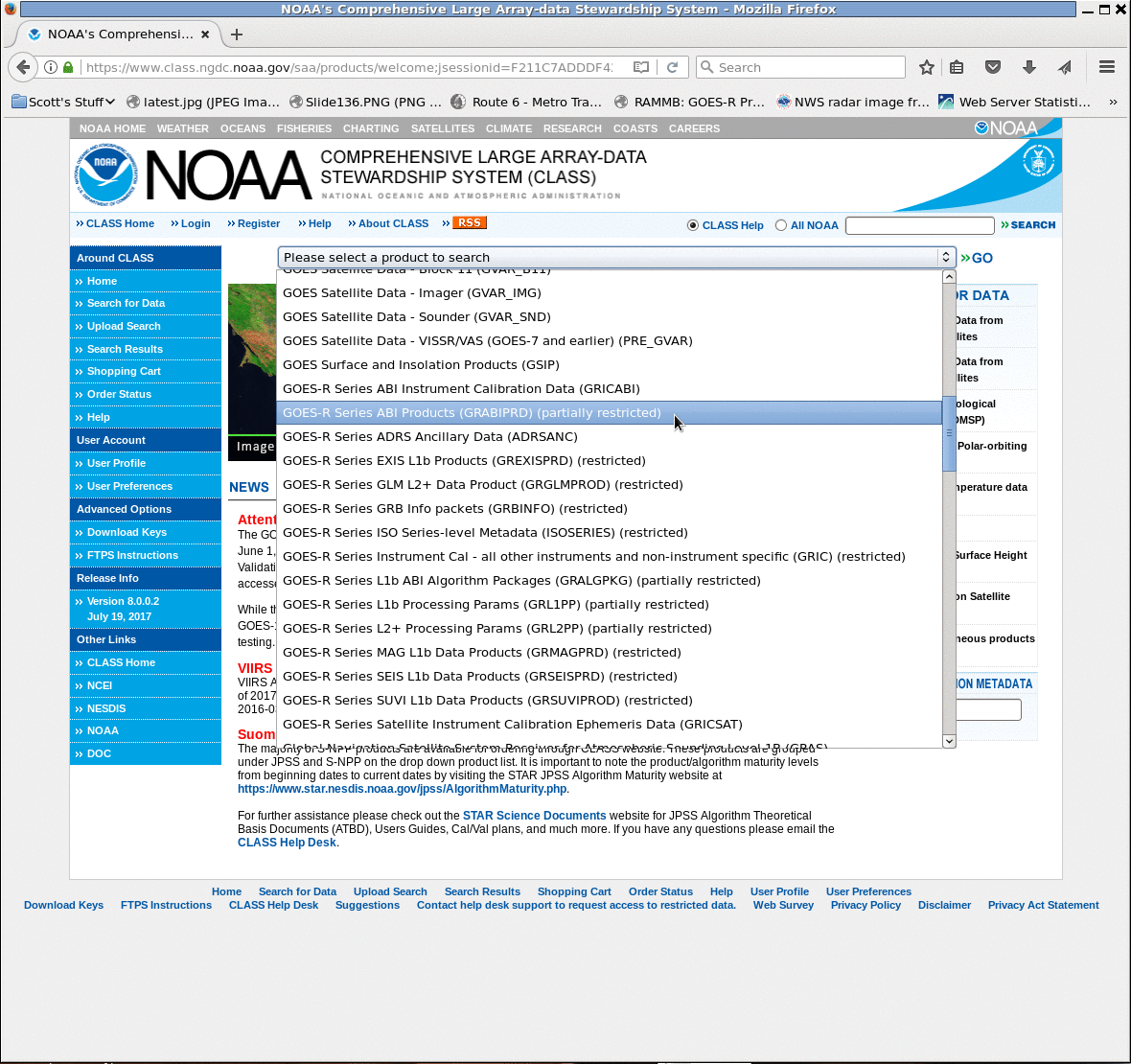
Once you’ve selected it — Click on the ‘Go’ that’s to the right of the Toolbar selection widget you’ve just used to select. That takes you to the page where you actually select which ABI data you want.
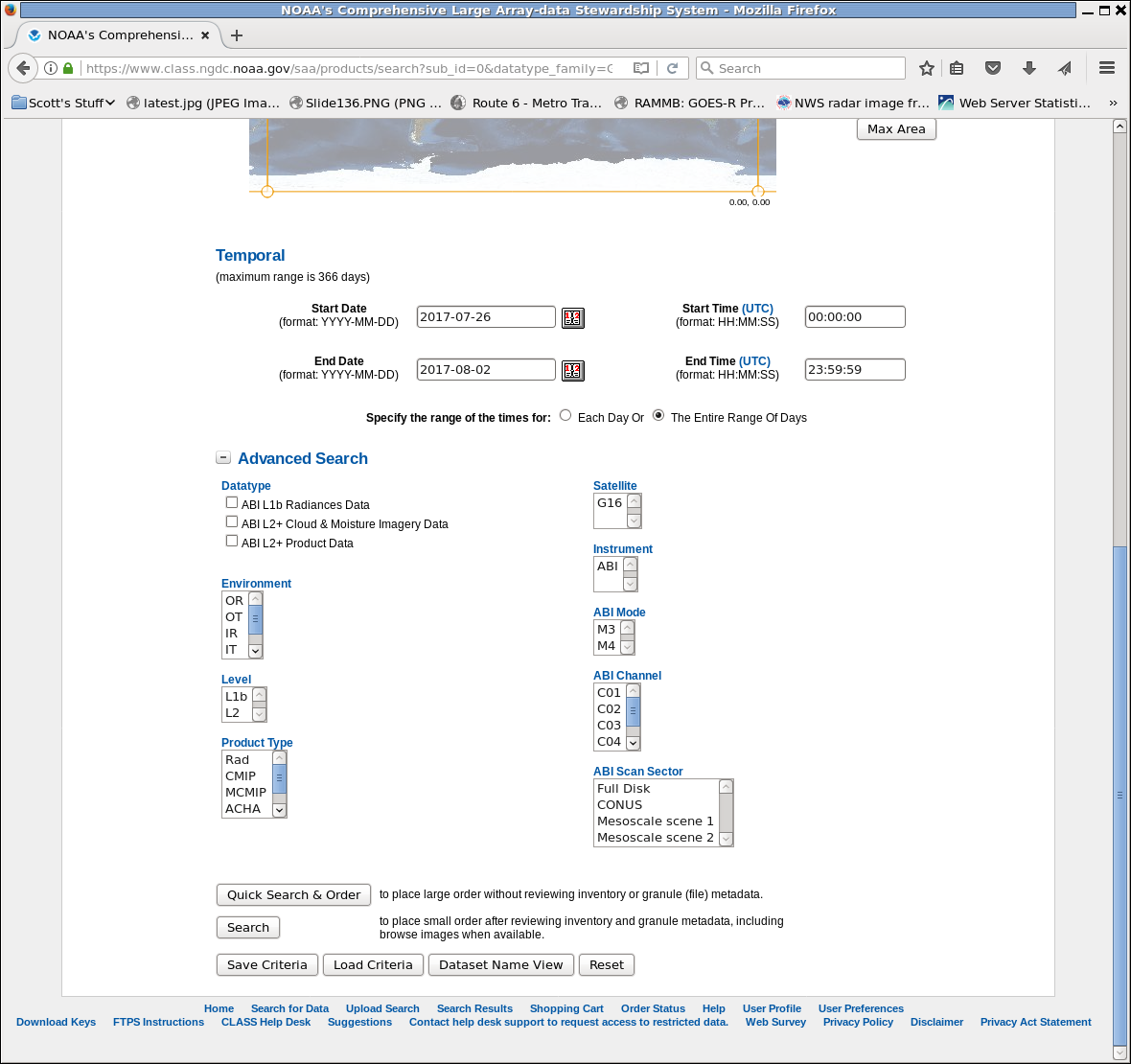
The data selection page is too long for one screen grab. Here’s the top of it. You can subsect the data, but I typically get an entire CONUS image, and subsecting is not necessary for that. So scroll down to the part that matters.
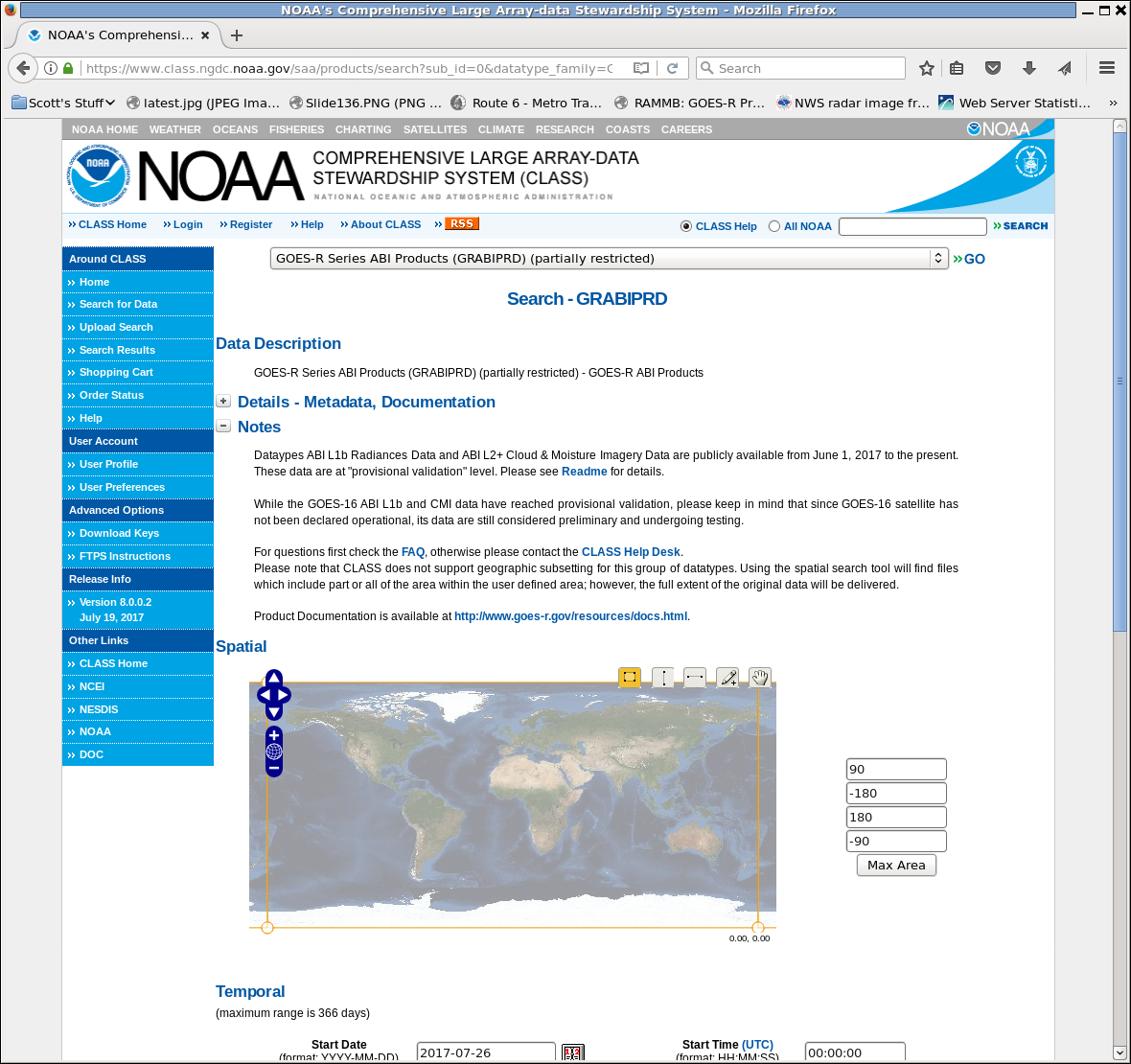
At the bottom of the page, there are places to select the times — Start/End Date, and State/End Times — and also the kind of data you want. ABI Data that displays in SIFT is ABI L1b Radiances Data — so tick that box under ‘Datatype‘! I also tick the ‘L1b‘ box under ‘Level’ and ‘Rad‘ under ‘Product Type’ (although that seems duplicative to me — if you select ABI L1b Radiances Data maybe it defaults to L1b for Level and Rad for Product type — but I’ve never tested that hypothesis.
The tick boxes on the right define the type of GOES-16 data you want. If you don’t click a box, you’ll get everything, and that’s a lot of data. Instead, make some decisions. CONUS Imagery? Full Disk? Meso Sectors? Mostly, Mode is M3 (Flex Mode); M4 is Full-Disk only mode. Channel has 16 choices. Eventually G17 will be in there too, of course.
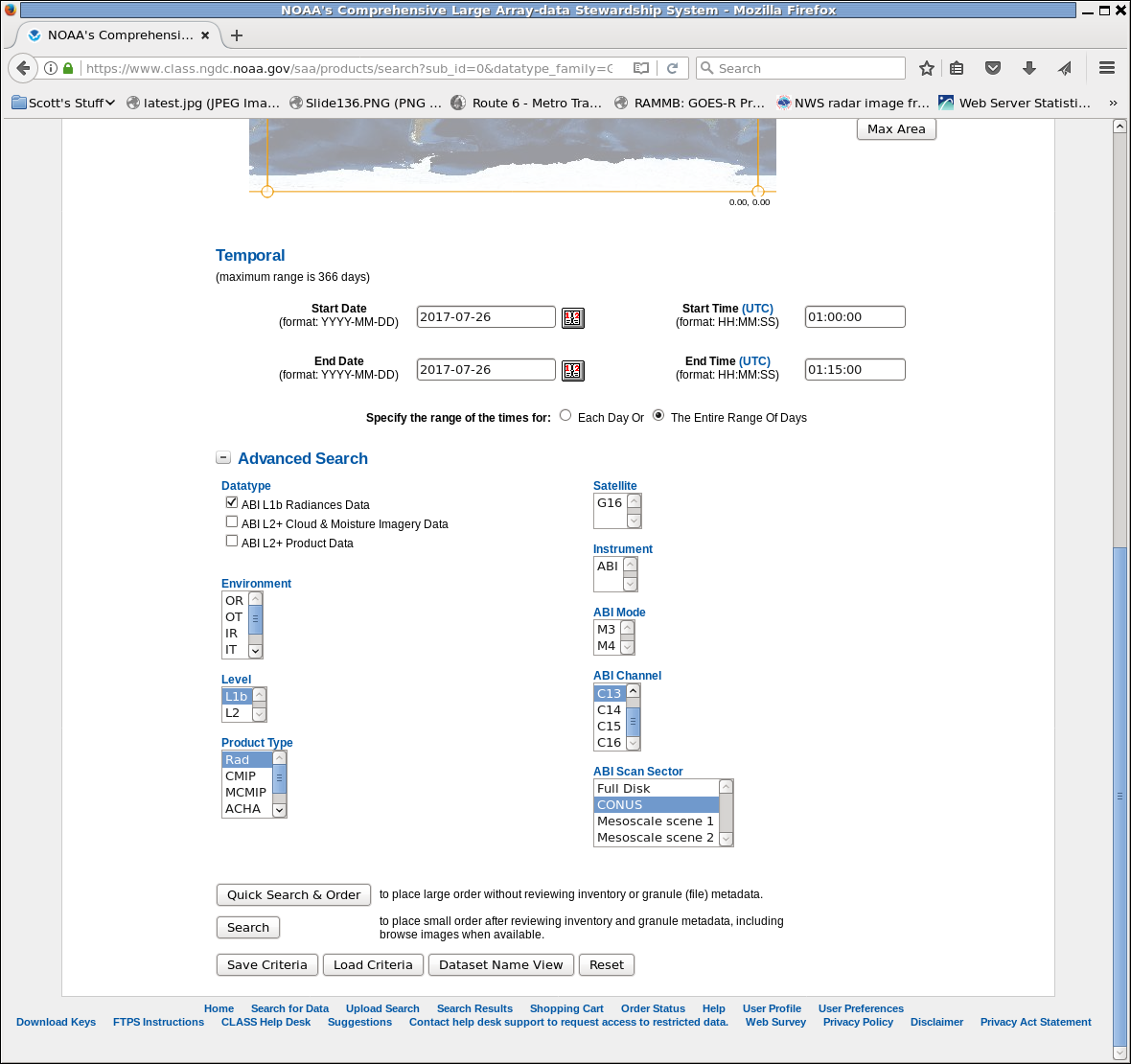
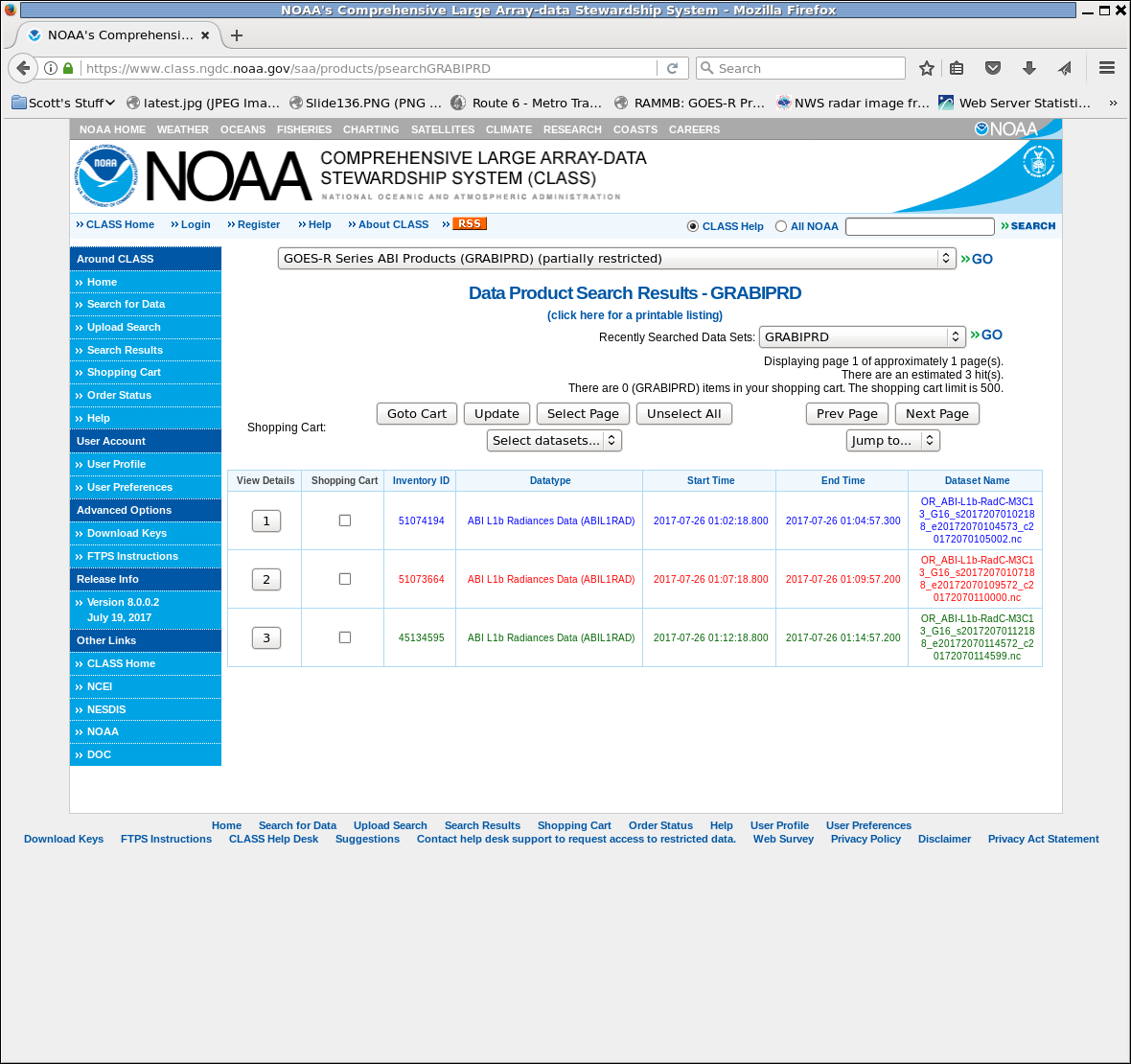
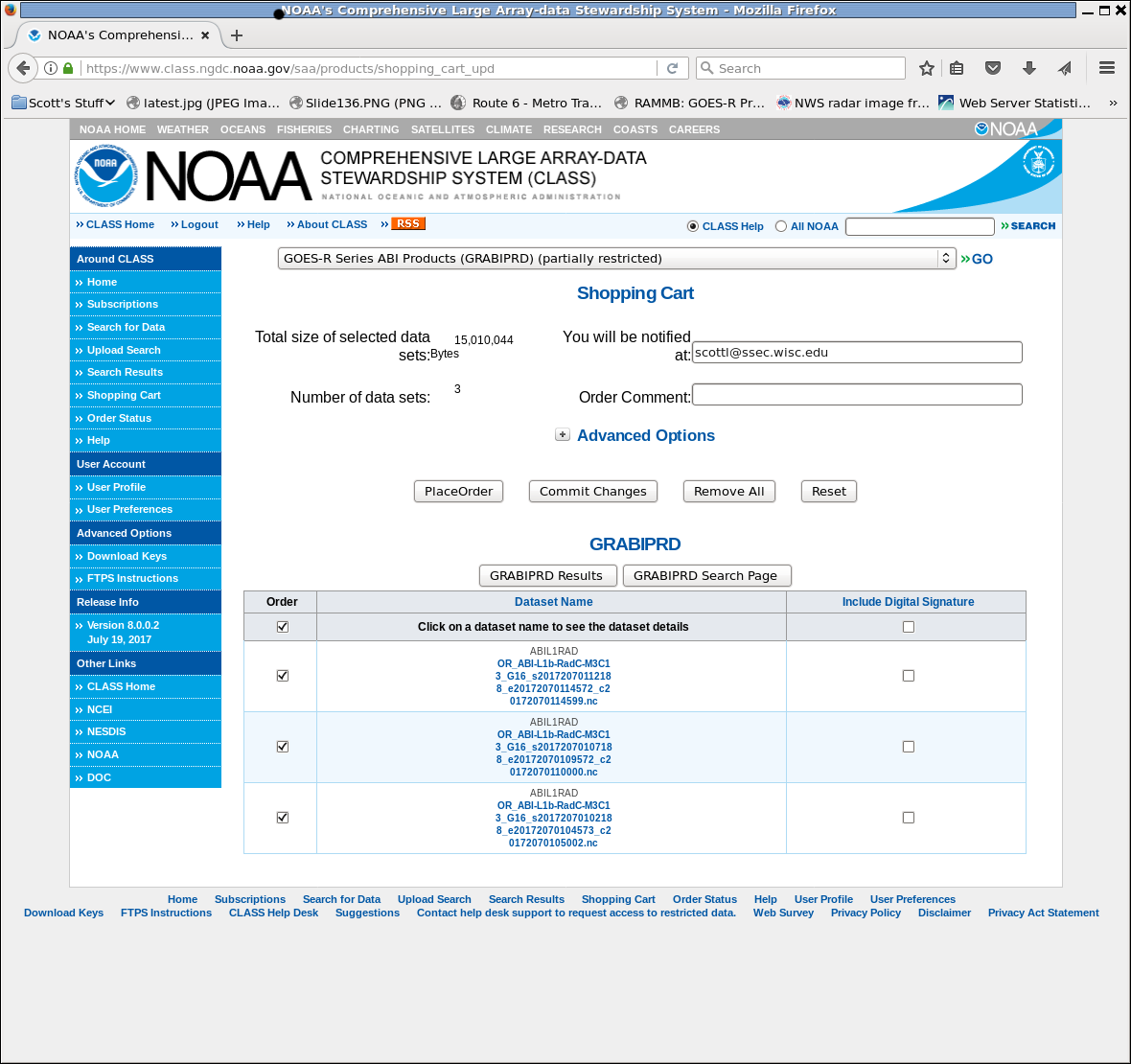
In the example above, I’ve requested Band 13 only, CONUS, from 01:00:00 to 01:15:00 on 26 July 2017. Because this is mode 3 data, that should be 3 images. Click ‘Quick Search & Order’ to get to the submit page, and sure enough there are 3 files there. Click on the ‘Shopping Cart’ boxes to put them into your Shopping Cart.
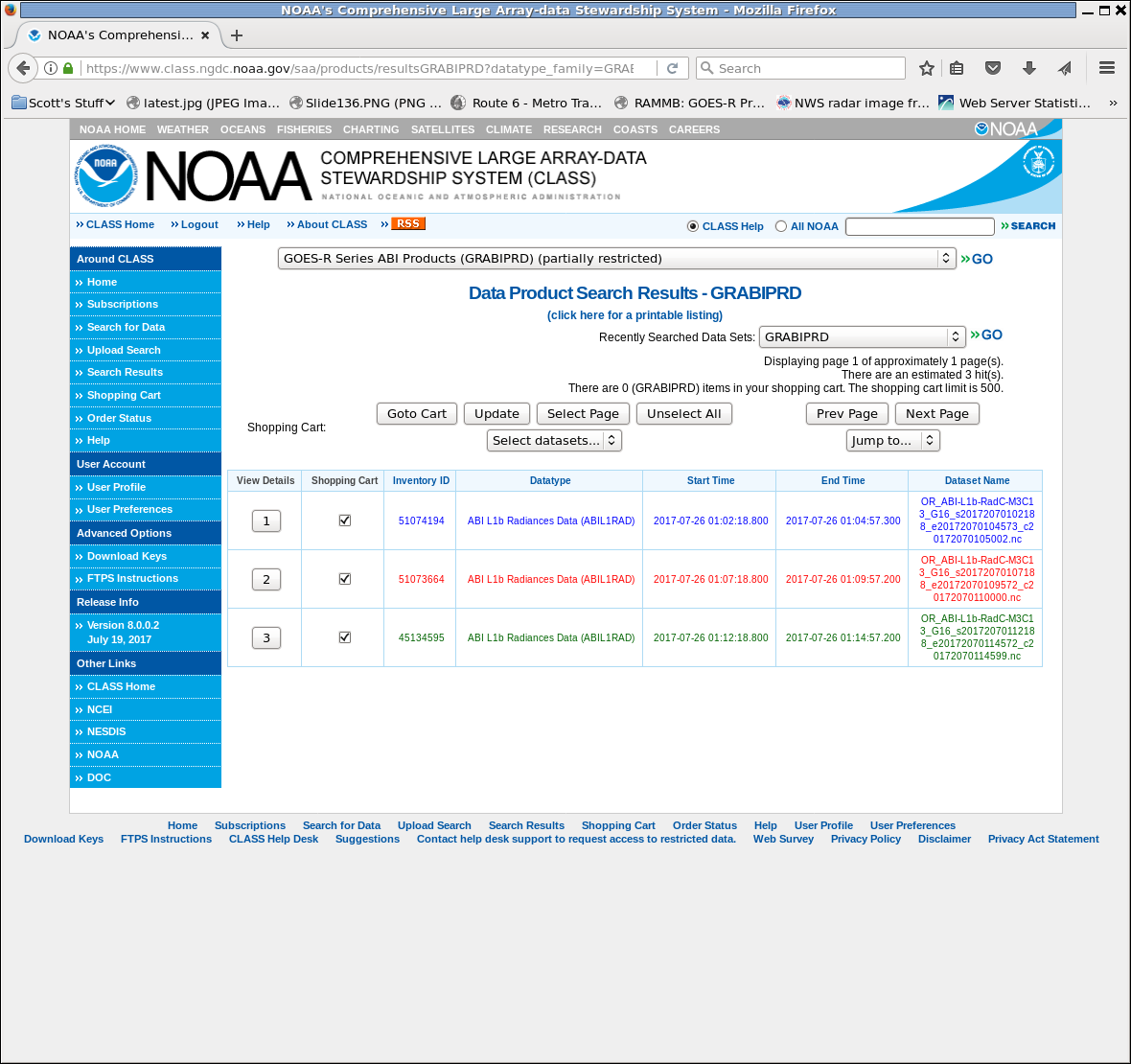
Note in the screengrab below that I’ve also logged into my account. I don’t think that’s strictly necessary, but why not set up an account? It streamlines the ordering process. So on the page below, satisfied that you’re getting the 3 files needed, click on ‘Goto Cart’
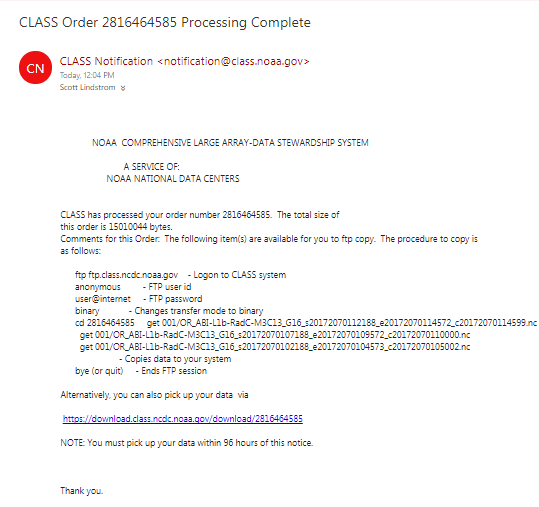
Here’s the actual submission. Note the notification email is there. You’ll get an email that the order has been submitted, then some time later (sometimes hours, but I’ve also received on in 5 minutes!), you’ll get another email that details how to get the data. Click on ‘PlaceOrder’ — and you’re almost ready to view the data in SIFT.
Here’s the email I received, saved as a png file:
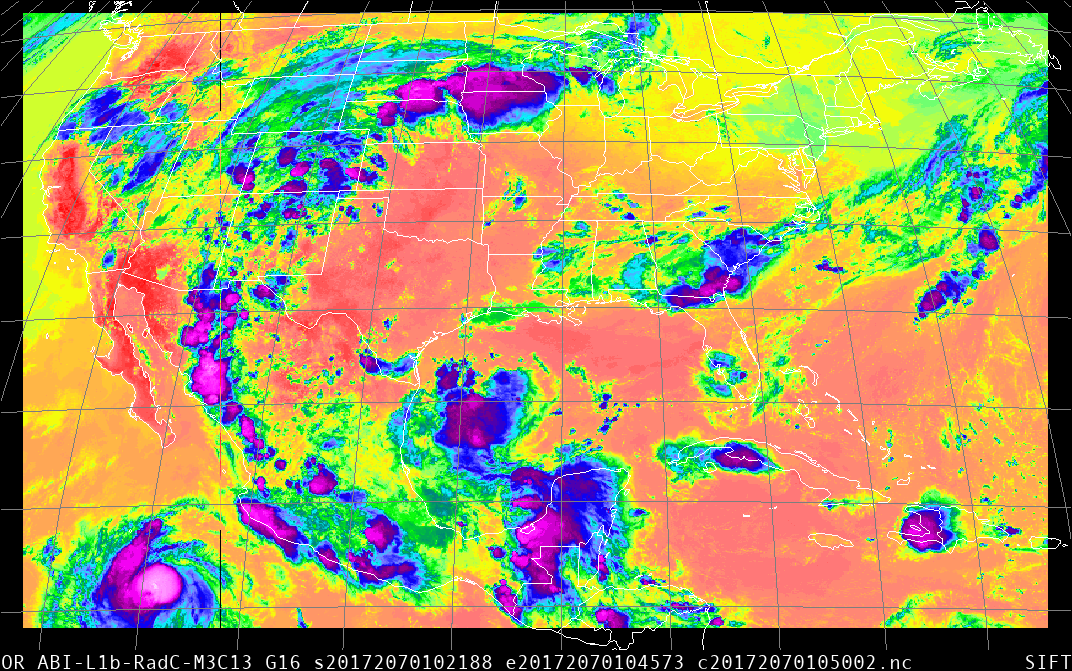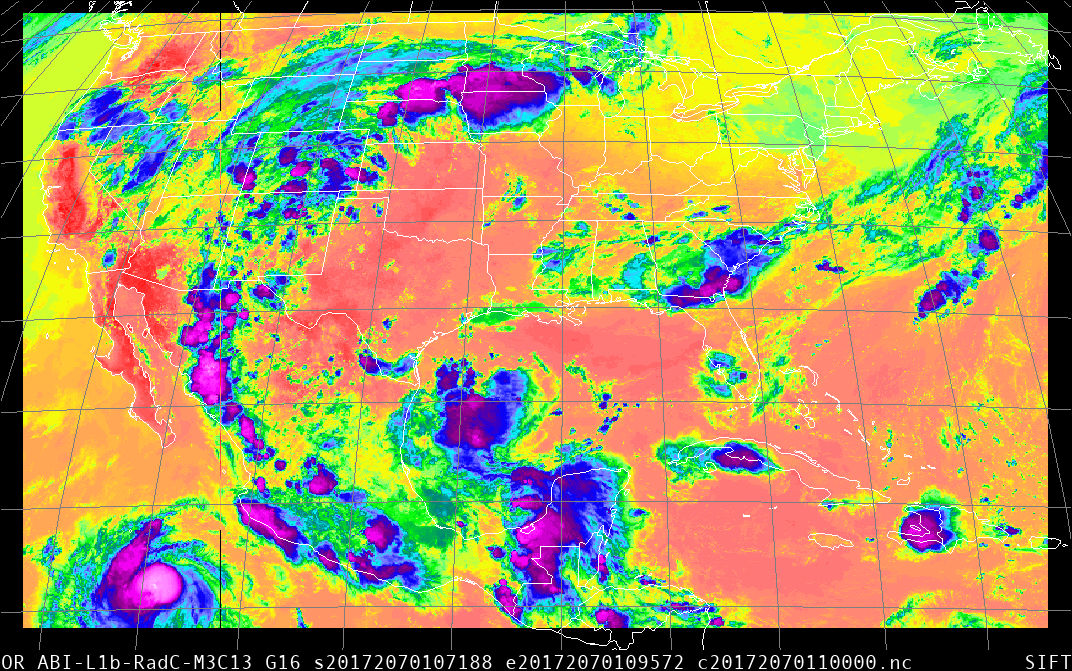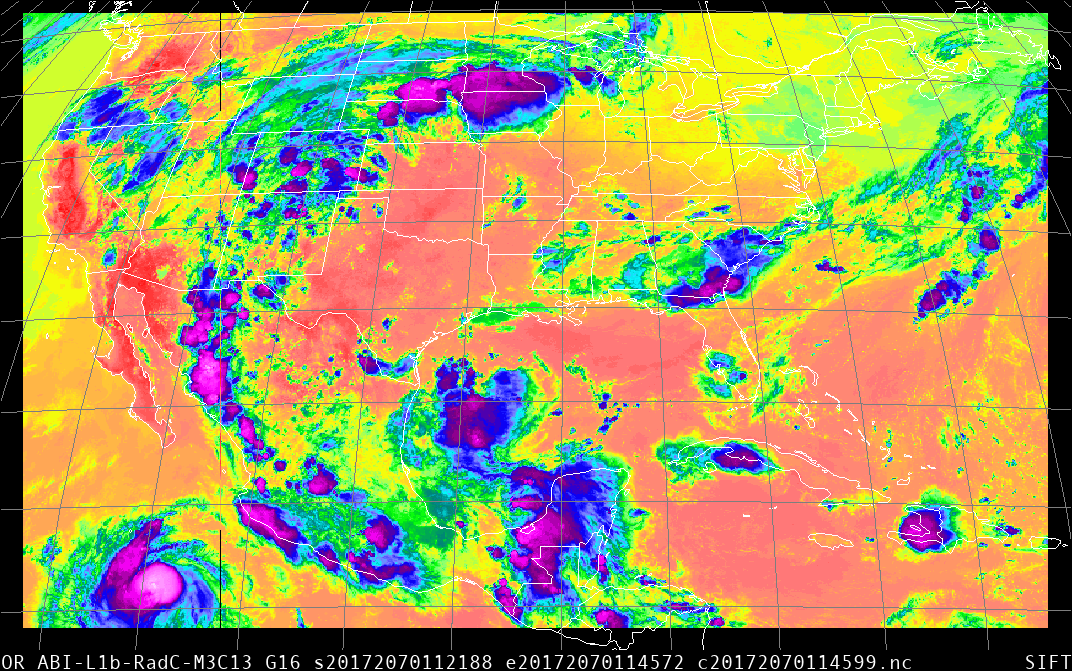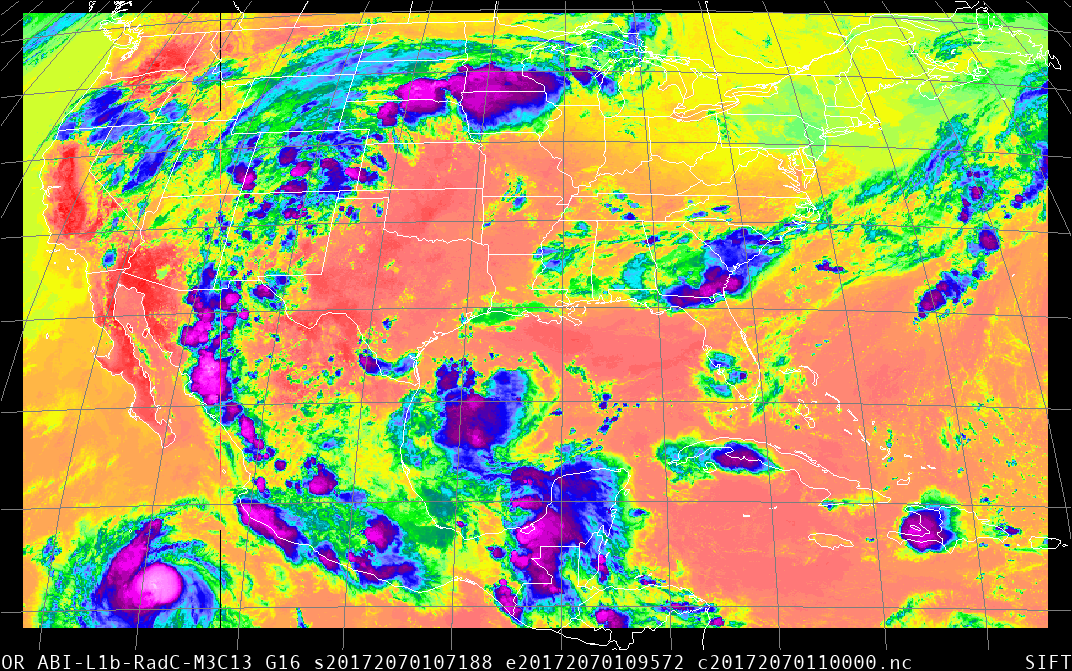
After downloading the three radiance files — and note that the files you download should have both Rad in the filename, and L1b — into SIFT, I get this animation:
Comments